

Un estudio a gran escala del efecto de los lenguajes de programación sobre la calidad del software que se produce se ha publicado este mes en el website de la ACM (Association for Computer Machinary). Y en este post presentamos algunas de sus principales conclusiones relacionadas con la prevalencia de los errores en los diferentes lenguajes.
Los investigadores Baishakhi Ray, Daryl Posnett, Premkumar Devanbu y Vladimir Filkov utilizaron datos de GitHub para una investigación empírica sobre el eterno debate presente entre los programadores en cuanto a qué lenguaje de programación es mejor para una tarea determinada. Combinaron el modelado de regresión múltiple con la visualización y la analítica del código, para estudiar el efecto de características del lenguaje tales como el tipado estático contra el tipado dinámico en calidad del software producido.
La versión corta de sus conclusiones se da en el resumen del paper presentado:
El diseño del lenguaje de programación tiene un efecto significativo pero modesto en la calidad del software. Lo más notable es que no permitir type confusion es modestamente mejor que permitirlo y entre los lenguajes funcionales, la tipificación estática es también algo mejor que la tipificación dinámica. También encontramos que los lenguajes funcionales son algo mejores que los lenguajes procedurales.
El objetivo de este estudio fue arrojar luz sobre la idea de que la elección del lenguaje de programación afecta tanto al proceso de codificación como al programa resultante, haciendo hincapié en la tipificación estática versus dinámica:
Los defensores de la tipificación fuerte y estática tienden a creer que el enfoque estático detecta los defectos temprano; para ellos, una onza de prevención vale una libra de cura. Los defensores de la tipificación dinámica argumentan, sin embargo, que la verificación conservativa del tipo estático es un desperdicio de recursos para los desarrolladores y que es mejor confiar en la comprobación de tipo dinámico fuerte para detectar errores de tipo a medida que surgen. Estos debates, sin embargo, han sido en gran parte de la variedad de los muchos, apoyados sólo por pruebas anecdóticas.
Para esta investigación, el equipo escogió los 19 lenguajes de programación más usados en GitHub, agregando a Typescript como el número 20 e identificó los 50 primeros proyectos escritos principalmente en cada uno de los lenguajes de programación seleccionados. Luego descartaron cualquier proyecto con menos 28 commits (el primer cuartil) y cualquier lenguaje utilizado en un proyecto multilingüe con menos de 20 commits en ese lenguaje.
Como se muestra en el cuadro a continuación, este estudio incluyó 728 proyectos desarrollados en 17 lenguajes de programación. Los proyectos abarcaron 18 años de historia e incluyeron 29,000 desarrolladores diferentes, 1,57 millones de commits y 564,625 commits de corrección de errores:
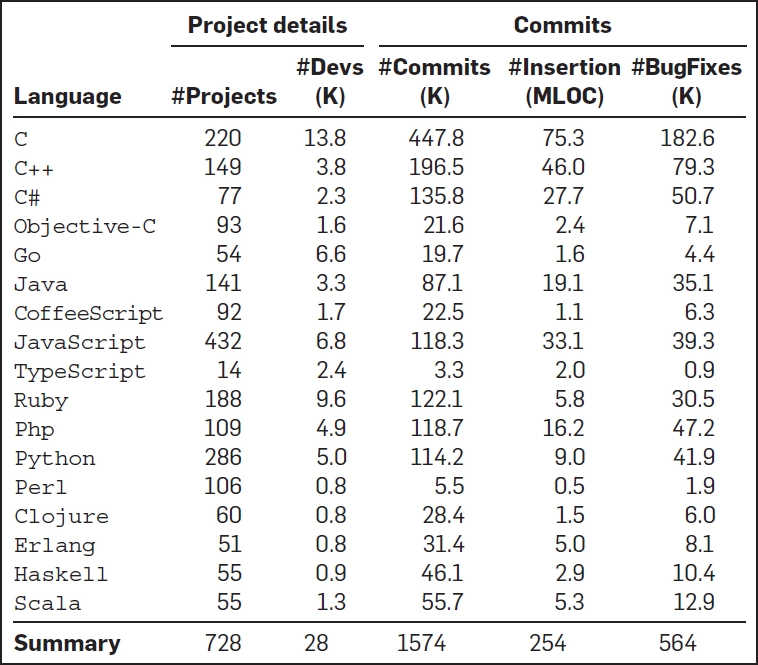
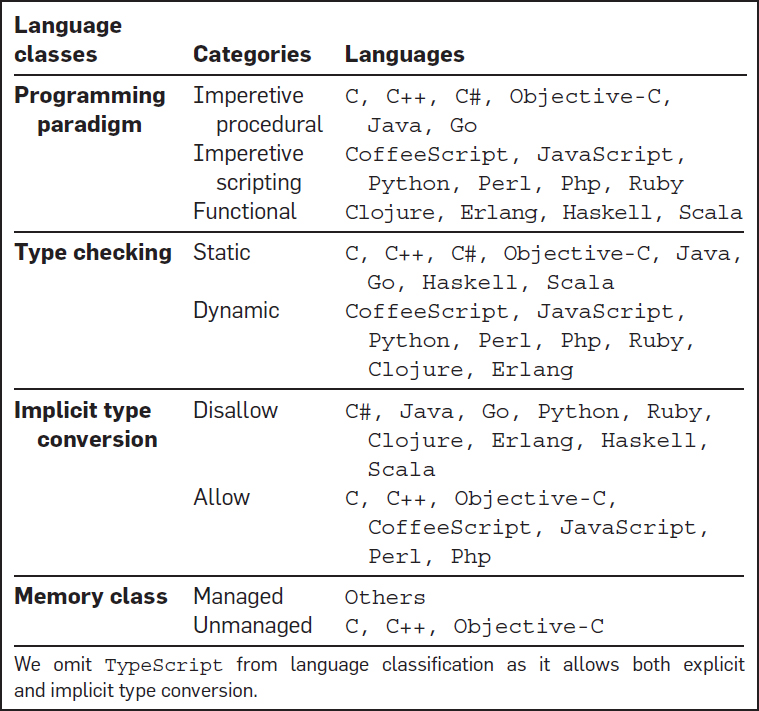
Luego, el equipo de investigadores definió las clases de idiomas, distinguiendo entre tres paradigmas de programación: procedural, scripting y funcional; dos categorías de comprobación de tipo: estática y dinámica; si la conversión implícita de tipos está prohibida o permitida y si la memoria es administrada en oposición a la no administrada, cómo resultado de este proceso se produjo la siguiente tabla de clasificación de los lenguajes:
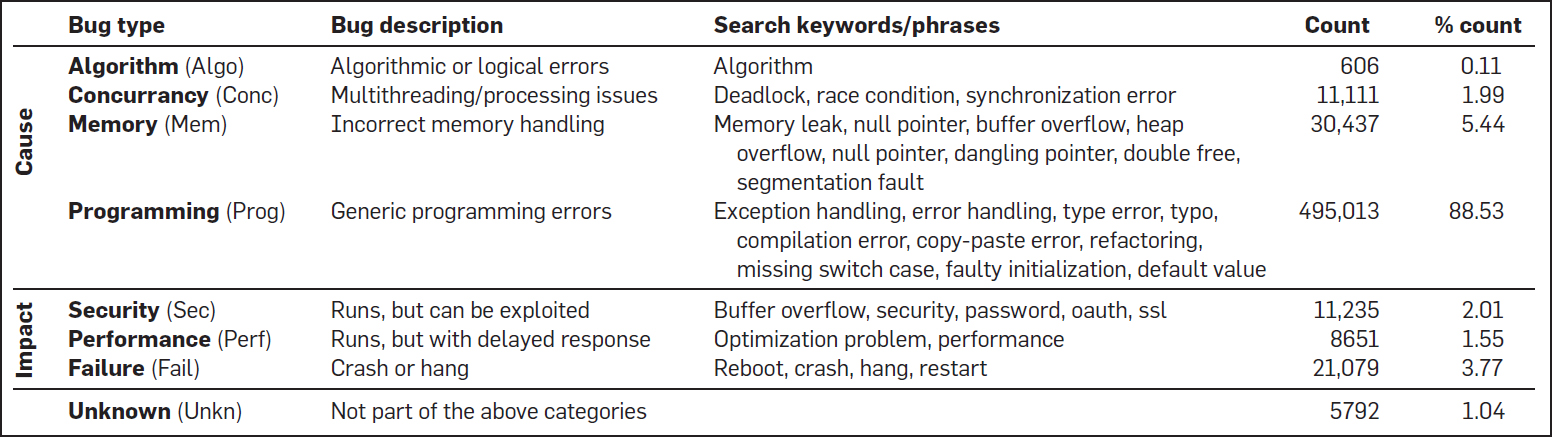
Utilizando la búsqueda de palabras clave para el 10% de los mensajes de corrección de errores para luego introducirlo en un clasificador de errores, los investigadores identificaron la causa y el impacto de cada commit en la correción de errores. El siguiente cuadro resume sus resultados:
La primera pregunta que trata de abordar este estudio es «¿Son algunos lenguajes de programación más propensos a errores que otros?» y esto se hizo utilizando un modelo de regresión para comparar el impacto de cada lenguaje en el número de errores, con el impacto medio de todos los lenguajes, contra la corrección de errores en los commits:
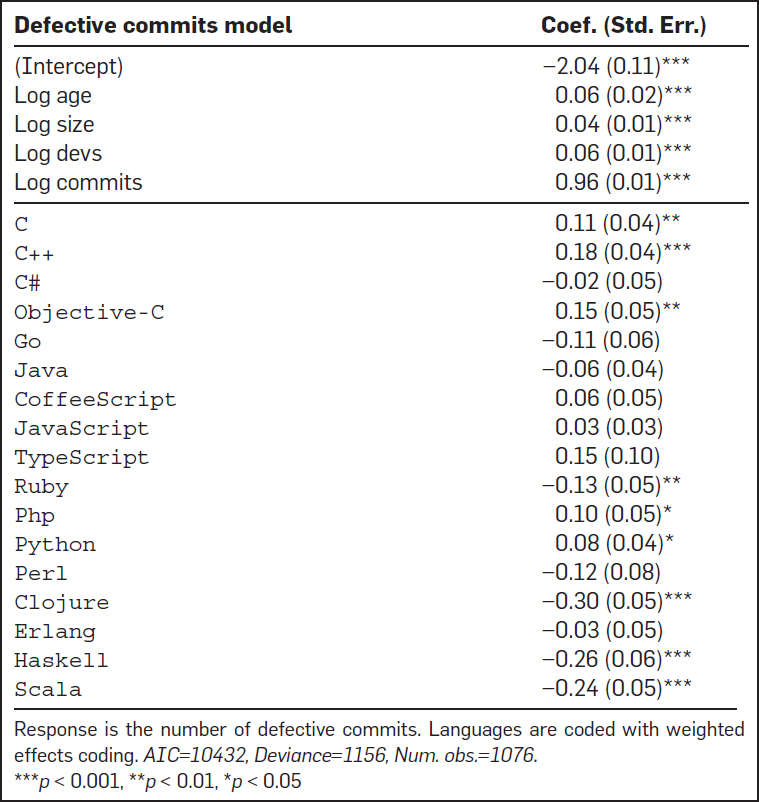
En la parte superior de la tabla mostrada arriba de este párrafo, se encuentran las variables que se utilizan como controles para los factores que pueden estar correlacionados. La edad del proyecto se incluye ya que los proyectos más antiguos generalmente tendrán un mayor número de correcciones de errores; el número de desarrolladores involucrados y el tamaño bruto del proyecto también se espera que afecten el número de errores y finalmente el número de commits está presente. Se encontró que los cuatro tenían coeficientes positivos significativos. Los lenguajes con los coeficientes positivos más fuertes, es decir, asociados con un mayor número de correcciones de errores son C ++, C y Objective-C, también PHP y Python. Por otro lado, Clojure, Haskell, Ruby y Scala tienen coeficientes negativos significativos que implican que estos lenguajes son menos propensos que el promedio a dar lugar a corrección de errores en los commits.Con respecto a las clases de lenguajes, los lenguajes funcionales se asocian con menos errores que los lenguajes procedurales o de scripting.
Los investigadores, luego volvieron su atención a la tendencia a producir errores de los lenguajes, la proporción entre los commits hechos para corregir errores y los commits totales por cada lenguaje y dominio y produjeron un mapa de calor donde el color más oscuro indica mayor propensión a los errores:
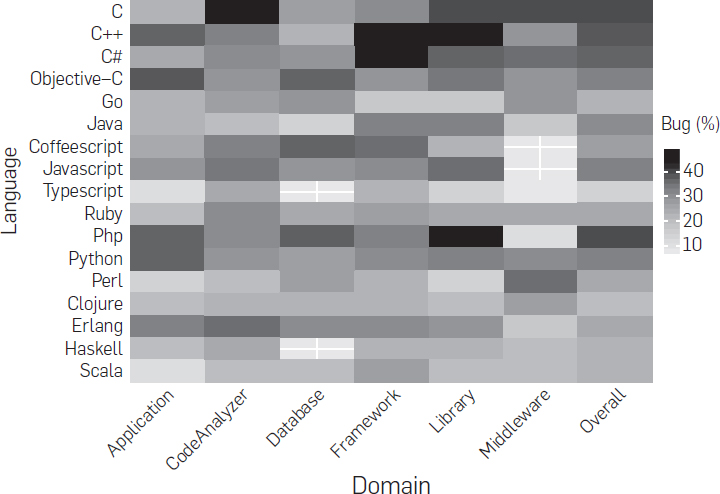
Del mapa de calor anterior, los investigadores concluyeron que no existe una relación general entre el dominio de la aplicación y la propensión a errores del lenguaje de programación. Sin embargo, si observamos la relación entre la clase de lenguaje y la categoría de errores, los investigadores indicaron que:
Los tipos de errores que están fuertemente asociados con los lenguajes, como algunos tipos de bugs como errores de memoria y de concurrencia también dependen de las primitivas del lenguaje. El lenguaje importa más para categorías específicas que para los defectos en general.
Dado que este mapa de calor muestra una fuerte relación entre la clase de lenguaje Procedural-Static-Implicit-Unmanaged y los errores de simultaneidad y memoria, también muestra que los lenguajes estáticamente tipados son en general más propensos a fallos y errores de rendimiento, a los que le siguen los lenguajes Functional-Dynamic-Explicit-Managed, como Erlang.
En resumen, las conclusiones del informe son las siguientes:
Los datos indican que los lenguajes funcionales son mejores que los lenguajes procedurales; sugiere que no permitir la conversión implícita de tipos es mejor que permitirlo; que el tipado estático es mejor que el dinámico y que el uso de memoria administrada es mejor que no administrado. Además, el hecho de que los lenguajes de programación en general no estén relacionadas con los dominios del software. Además, los lenguajes de programación están más relacionados con las categorías de errores individuales que con los errores en general.
Aquí termino mi resumen del extenso y detallado estudio, en caso se sientan interesados en conocer más y entender cómo se produjeron las estadísticas los remito al estudio original.